Collecting video clips
We divided 9,396 movie clips sourced from the Movieclips YouTube channel into training and testing splits, containing 9,248 and 148 videos respectively. Following our question-answer generation and filtering pipeline, we produced 298,888 training points and 4,940 test-set points, averaging about 32 questions per video scene.
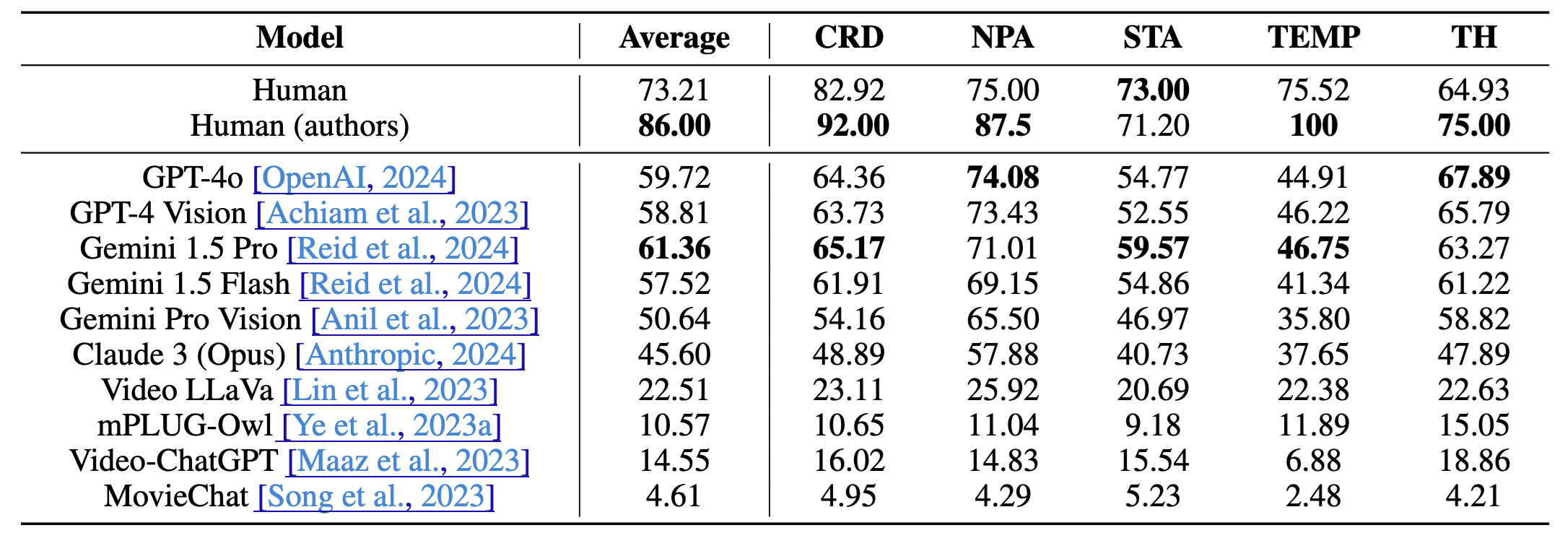
Dataset statistics
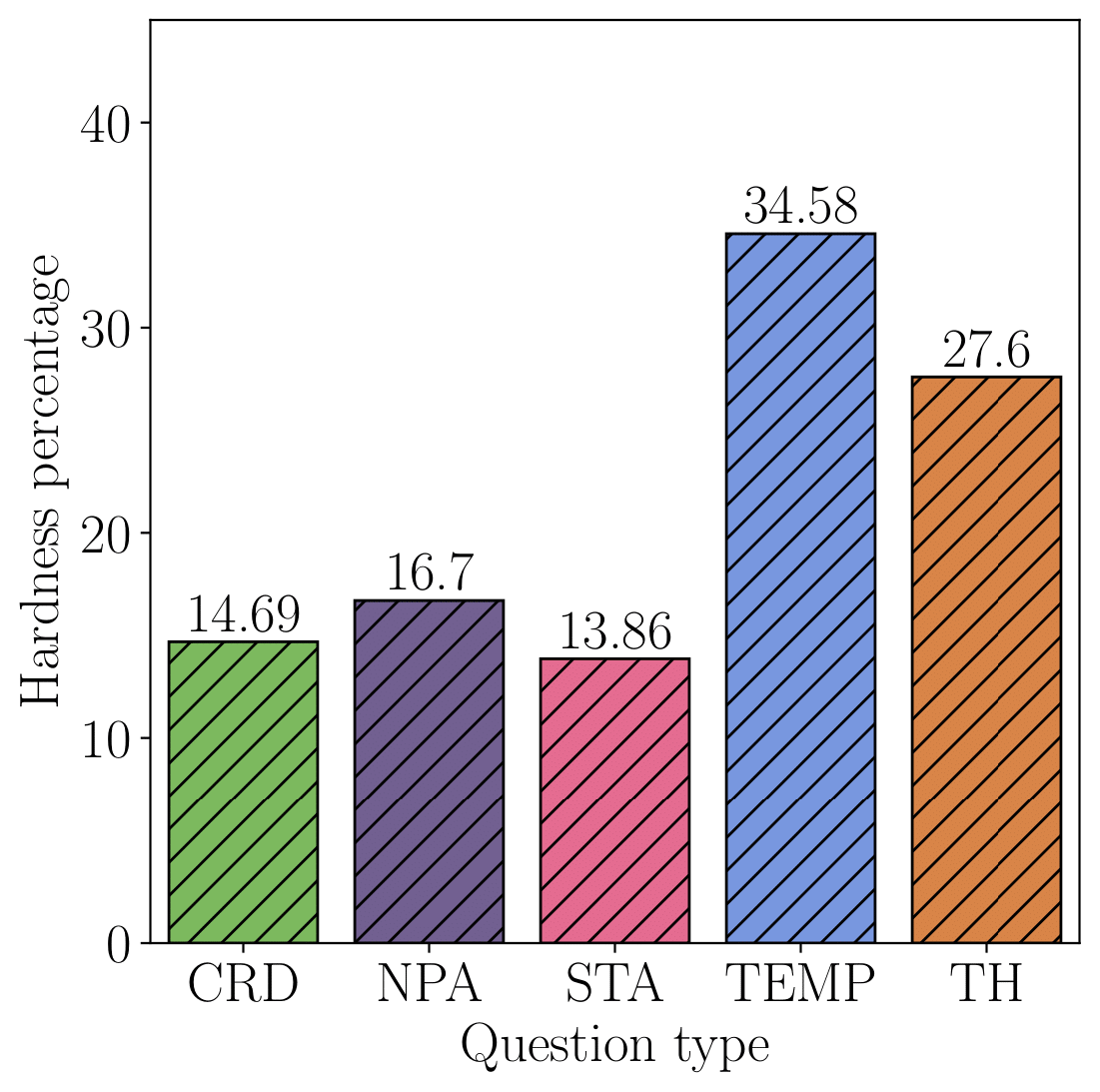
For each question, we provide additional information, such as whether the questions are particularly challenging to answer (hardness) or if they require visual information (visual reliance) for an accurate response.
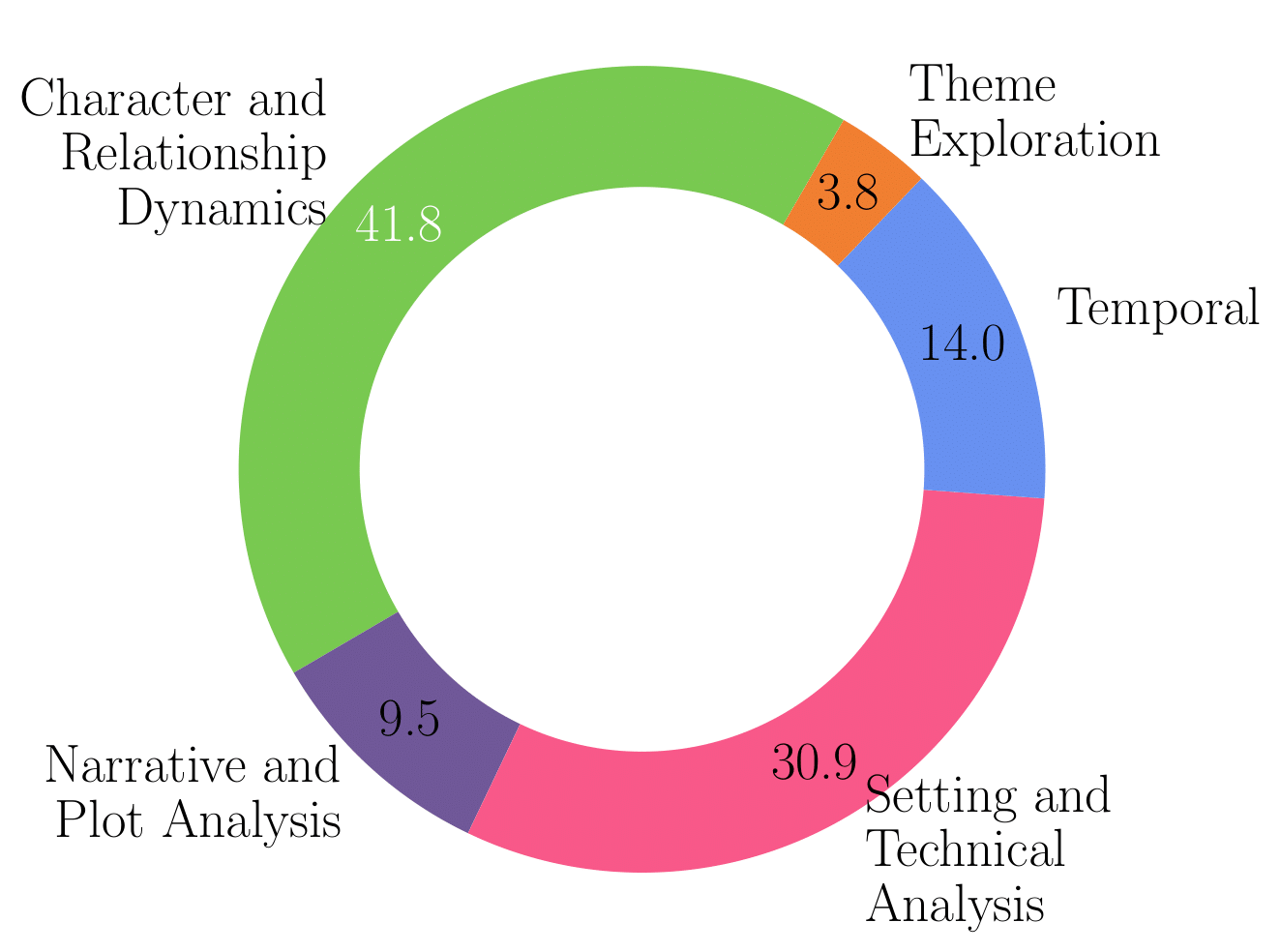
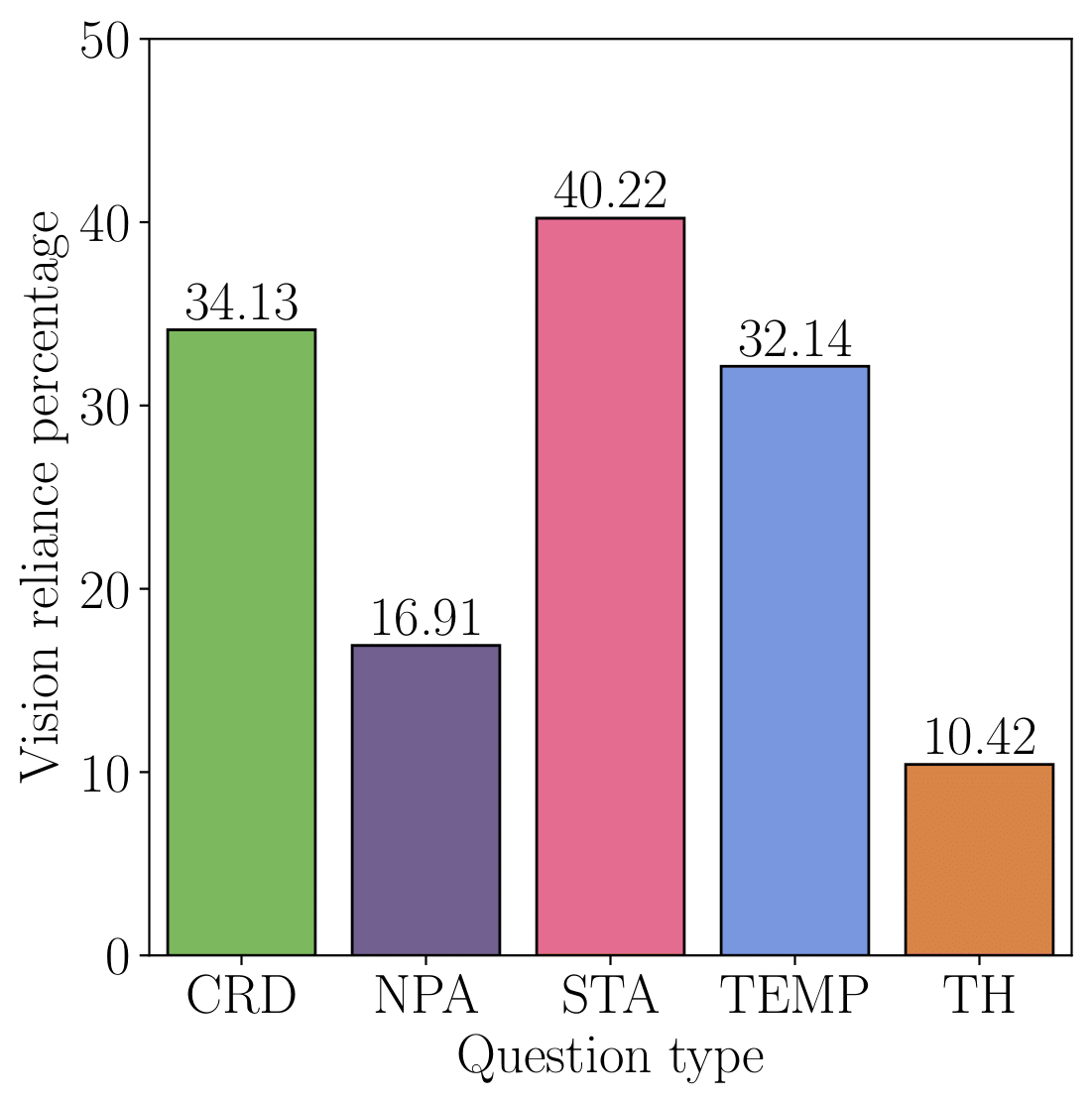
Model evaluation strategy
Given that our dataset is of type multiple-choice question answers (MCQs), we evaluate a given model’s performance on our benchmark questions by measuring its ability to accurately select the right answer from a set of multiple-choice options, containing only one correct answer and four distractors. Our evaluation method incorporates a two-stage process to first reliably extract the selected choice from a model's response, and then compare whether the extracted response matches the correct answer key.
Evaluation Results
Among the various commercial VLMs analyzed, GPT-4o, GPT-4 Vision and Gemini 1.5 Pro (Video) emerge as top performers, each achieving around 60% average performance. We note that all the models observe a drop of 15%-20% when evaluated on the hard split.